本篇目录:
spring利用jdbctemplate实现批量插入怎么存储时间
批量插入并返回批量id的方法需要改写返回值:注:由于JDBCTemplate不支持批量插入后返回批量id,所以此处使用jdbc原生的方法实现此功能。
一列为id,一列为name。那么你的sql语句就可以写成insert into student values (student_seq .nextval, ?); 也就是说你用jdbcTemplate只需要设置name的值就行了,id是通过调用序列来插入的(即交给oracle解决)。
-图1")
可以使用JdbcTemplate类的execute()方法重新执行SQL语句,将数据入库。通过JdbcTemplate的batchUpdate()方法,也可以实现批量添加数据的功能。
JdbcTemplate将我们使用的JDBC的流程封装起来,包括了异常的捕捉、SQL的执行、查询结果的转换等等。spring大量使用Template Method模式来封装固定流程的动作,XXXTemplate等类别都是基于这种方式的实现。
jdbc连hive怎么批量插入
1、JDBC连接的方式,当然还有其他的连接方式,比如ODBC等, 这种方式很常用,可以在网上随便找到,就不再累赘了。不稳定,经常会被大数据量冲挂,不建议使用。
-图2")
2、如果要写入到hive的话,就需要将不同的表的binlog写入到不同的hive表中,这个维护成本太高了。而且spark其实可以直接读取hdfs的json文件,因此直接放hdfs就好了。
3、在表中输入数据:我们已经显示了如何通过指定列名、数据类型来创建表 COFFEES,但是这仅仅建立表的结构。表还没有任何数据。
4、因此,就产生的JDBC连接的方式,当然还有其他的连接方式,比如ODBC等。
-图3")
5、这里所说的在Java中执行Hive命令或HiveQL并不是指hive Client通过JDBC的方式连接HiveServer(or HiveServer2)执行查询,而是简单的在部署了HiveServer的服务器上执行Hive命令。
6、写入和管理驻留在分布式存储中的大型数据集。可以将结构投影到已存储的数据上,提供命令行工具和JDBC驱动程序,用于将用户连接到Hive。最适用于传统的数据仓库任务。Hive优势在于处理大数据,因为hive的执行延迟比较高。
java中怎么一次性向表中插入一条或多条数据
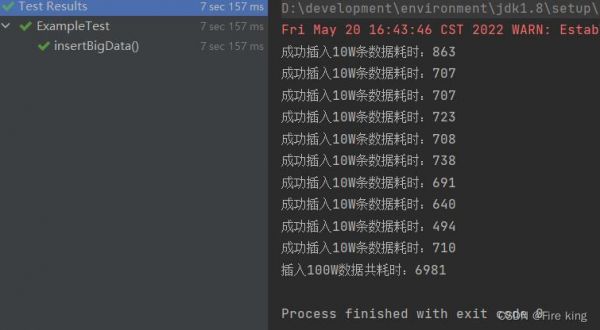
1、PreparedStatement.addBatch(); ... PreparedStatement.executeBatch();需要注意的是一次最多不要超过50条:因为插入的时候数据库已经锁定,然而若是一次性插入太多会造成其他业务的等待。
2、jTablesetModel(new javax.swing.table.DefaultTableModel(object, string));写的方法对object二维数据赋值就行了。同样若是想把表中的数据读出来就是遍历object这个二维数组。
3、字段值1,字段值2,字段值3),(另一个字段1的值,另一个字段2的值,另一个字段3的值)...;但是这是非标准的写法,并不提倡。所以,你只需要把需要插入的数据按顺序写到执行语句固定的位置,然后执行就可以了。
4、实在要输入几多个数组,不必用第一个输入的数来做控制。
5、实现思路:首先oracle数据库中的插入数据可以用insert语句,之后即可通过java方式进行插入,如:String userinfo=insert into userinfo VALUES(++userD+,sysdate+);//之后执行插库操作。
到此,以上就是小编对于jdbc批量添加数据的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位老师在评论区讨论,给我留言。
 微信扫一扫打赏
微信扫一扫打赏